When a system becomes fragile, many teams feel trapped between two bad options:
- Keep patching the old system forever
- Rewrite everything and hope the migration works
There’s a safer third option:
Modernise gradually while the business keeps running.
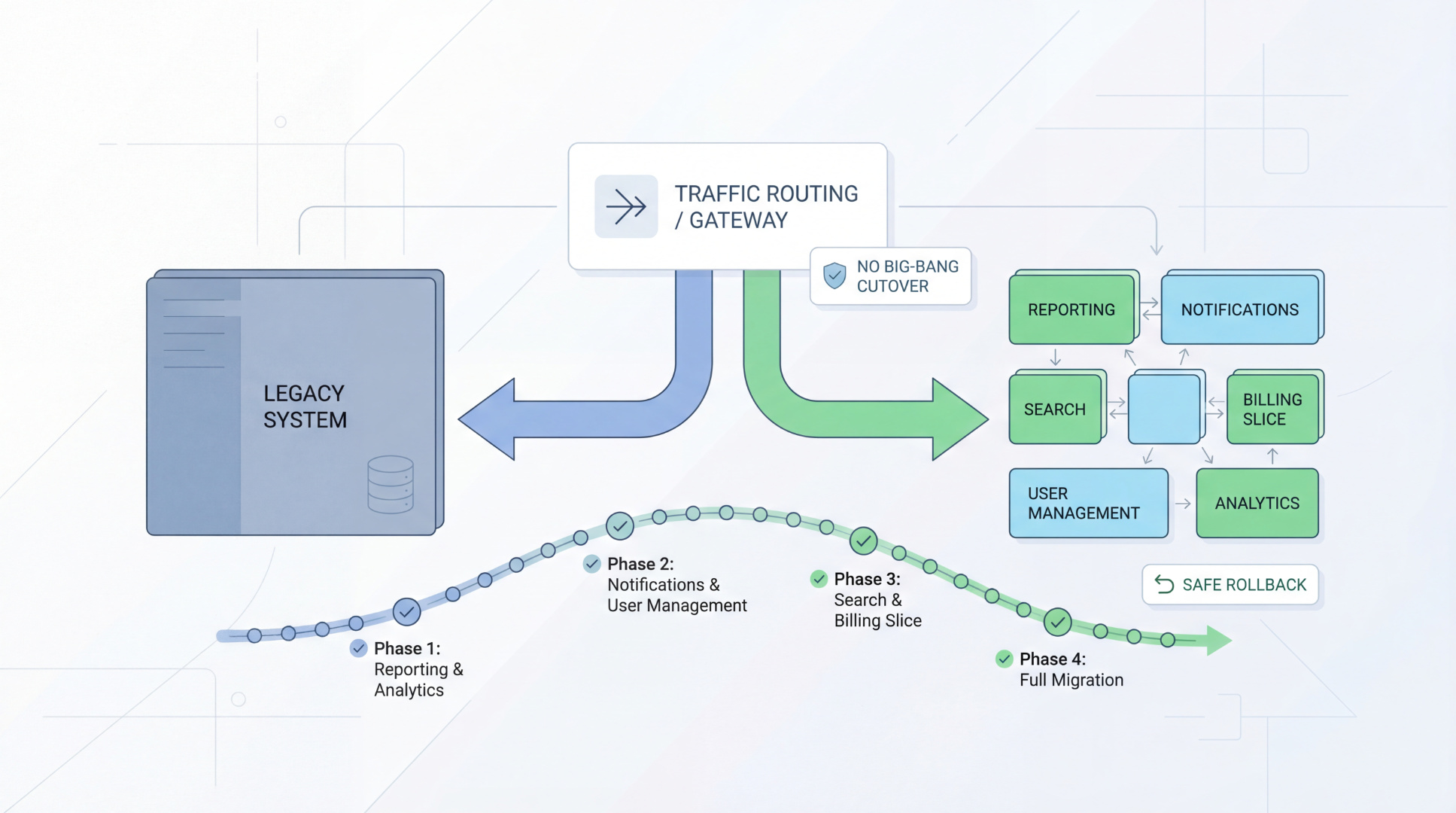
One of the most effective ways to do that is the Strangler Fig Pattern — a practical approach for replacing parts of a legacy system step by step, without a risky “big bang” switch-over.
This post explains the idea in plain language and shows how SMEs can use it to reduce risk, protect revenue, and modernise with confidence.
What is the Strangler Fig Pattern?
The name comes from a strangler fig tree, which grows around another tree over time and gradually replaces it.
In software, the idea is similar:
- keep the existing system running
- build new functionality around it
- route selected traffic to the new component
- gradually move more responsibility out of the old system
- retire old parts when they are no longer needed
Instead of replacing everything at once, you replace it in slices.
Why this approach works for SMEs
SMEs usually can’t pause the business for a year while a rewrite happens.
You still need to:
- ship features
- support customers
- fix bugs
- handle integrations
- respond to market changes
The Strangler approach works because it allows you to modernise without stopping delivery.
Business benefits
- lower migration risk
- fewer outages during transition
- visible progress (small wins)
- easier budgeting (incremental investment)
- faster learning (adjust the plan as you go)
The core idea: replace by business capability, not by technology layer
A common mistake is to start with technical layers:
- “Let’s move the database first”
- “Let’s rebuild the framework”
- “Let’s switch to a new stack”
That often creates a lot of effort before the business sees any value.
A better approach is to extract business capabilities such as:
- notifications
- reporting
- search
- authentication
- invoicing
- a specific checkout step
- admin workflows
These are easier to reason about because you can measure impact:
- fewer incidents
- faster changes
- improved conversion
- reduced support load
What a strangler migration looks like (simple version)
Here’s the pattern in practice:
1) Keep the legacy system as the source of continuity
The current system continues serving users. No big cutover.
2) Introduce a routing layer (or gateway)
A router decides where requests go:
- old system
- new component/service
At first, most requests still go to the old system.
3) Build one new slice
Choose a narrow capability (for example: notifications). Build it in the new architecture with:
- tests
- monitoring
- safe deployment process
4) Route only that slice to the new component
Now one area is modernised, while the rest stays in the legacy system.
5) Observe, stabilise, expand
Measure outcomes, fix issues, then repeat with the next slice.
This is how you modernise without downtime and without betting the company on one release.
What to migrate first (SME-friendly priorities)
You don’t need to start with the most complicated area. Start with the best risk-to-value ratio.
Good first candidates are usually:
Option A: High-change, low-complexity areas
These give fast wins and prove the process.
- notifications
- simple admin tools
- reporting exports
Option B: High-pain incident hotspots
If one part repeatedly breaks, isolating it can reduce risk quickly.
- payment retries
- order sync jobs
- external API integrations
Option C: Boundaries that are already semi-separate
If an area already has a clear interface, extraction is easier.
- search
- media processing
- email sending
Avoid first (usually)
- core billing logic with undocumented edge cases
- deeply entangled workflows
- anything with unclear ownership and no tests
The operational basics you need before extraction
The Strangler pattern is safer than a rewrite, but it still needs discipline.
Before you extract slices, make sure you have:
1) Observability
You need to see what’s happening:
- logs
- metrics
- alerts
- request tracing (even basic tracing helps)
2) Safe deployment practices
- rollback plan
- small releases
- clear release ownership
- staging/testing flow
3) Behaviour protection (tests)
Before replacing a legacy slice, capture its critical behaviour so you don’t accidentally remove something the business depends on.
4) Clear ownership
Each new slice should have one team/person accountable for:
- delivery
- support
- fixes
- monitoring
Common mistakes (and how to avoid them)
Mistake 1: Extracting by technology, not business value
Fix: choose slices that reduce risk or improve delivery speed.
Mistake 2: Creating a distributed monolith
This happens when services are “separate” but still tightly coupled.
Fix: define clear boundaries and keep interfaces simple.
Mistake 3: No monitoring during migration
If you can’t compare old vs new behaviour, issues will be hard to diagnose.
Fix: add logging/metrics before cutover.
Mistake 4: Migrating too much at once
Big batches recreate the same risk as a rewrite.
Fix: small slices, short feedback loops.
Mistake 5: Forgetting rollback/fallback
Every migration step should have a safe way back.
Fix: keep legacy path available until the new slice proves itself.
A practical 90-day example (SME scale)
Here’s what a realistic first phase might look like:
Weeks 1–2: Risk mapping + candidate selection
- identify incident hotspots
- choose one slice (e.g., notifications)
- define success criteria
Weeks 3–4: Stabilise and instrument
- add logs/metrics
- add tests around current behaviour
- prepare routing strategy
Weeks 5–8: Build and deploy the first slice
- implement the new component
- deploy with monitoring
- route a small % or selected traffic
Weeks 9–10: Validate and improve
- compare outcomes
- fix edge cases
- document lessons learned
Weeks 11–12: Plan the next slice
- choose the next capability
- refine the migration playbook
- repeat with more confidence
That’s meaningful modernisation — without a rewrite programme consuming the whole business.
What leaders should ask during a strangler migration
If your team or vendor proposes an incremental migration, ask:
- What slice are we extracting first, and why this one?
- What business risk or cost does this reduce?
- How will we route traffic safely between old and new?
- How will we detect if behaviour changes unexpectedly?
- What is the rollback/fallback plan?
- What will success look like in 30/60/90 days?
These questions keep the migration grounded in outcomes, not architecture buzzwords.
The takeaway
The Strangler Fig Pattern gives SMEs a practical path between “do nothing” and “rewrite everything.”
It helps you:
- modernise incrementally
- reduce downtime risk
- keep the business moving
- build confidence with each step
You don’t need a perfect future-state architecture on day one.
You need a safe way to replace the next risky part — and then the next one after that.